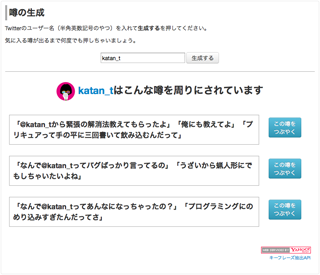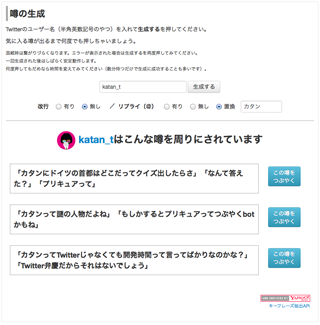
今もたくさんの方に遊んでいただいています。
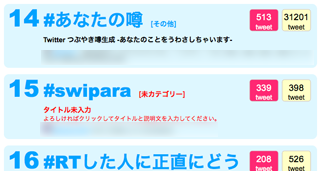
ハッシュタグクラウドというハッシュタグランキングサイトの集計によりますと、公開1週間で本コンテンツのハッシュタグである
#あなたの噂が30000回以上つぶやかれたそうです。
テレビ番組でも仲間探しでもなんでもない、とある一つのWebコンテンツのハッシュタグがここまで流れるのはそこそこ珍しいのではないかと思います。
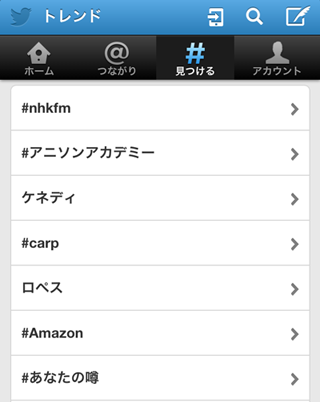
↓は公開約一週間時点のハッシュタグクラウドのスクリーンショットです。
びっくりなことに公開10日後の4月20日にはTwitterのトレンド(日本)に載ってしまいました。
Twitter史に名を刻んだ気分ですね(大げさ)。
遊んでいただき心より感謝申し上げます。
正直ここまで遊んでもらえたのはかなりびっくりな結果でした。胸の高鳴りが一年分ぐらいまとめて押し寄せた感じです。
公開から数日は本当にばたばたしました。
ということで、せっかくなので、ばたばたしないために私がどんな準備をして、しかし結局ばたばたしてどういう対応をとったのか、それを時系列でまとめてみました。
Twitter関連でWebサービスを公開する人のためのノウハウ集!
と声高らかに宣言できればいいんですが、実際にはどたばたのすべてが私の準備、経験、知識の不足に帰結するという……恥ずかしさ満載!
まあ、同じ過ちを犯さずに済むようにという自戒も込めての公開です。
ちなみに私の専門はFlashです。噂生成ではまったく使っていないですが。
コンテンツ概要
Twitterのアカウント名を入れるとつぶやきを引っ張ってきてキーフレーズ抽出してそれを文章に当てはめて表示、といういわゆる診断系?のコンテンツです。
処理は大まかに書くと下記の流れ。
- クライアント側でTwitterのアカウント名を入力してサーバに送信。
- サーバ側でそのアカウント名を元にTwitterのAPIを呼び、つぶやきを取得。
- つぶやきをちょい加工してYahooのAPIを呼ぶ。
- 返ってきたキーフレーズを元に生成した噂をクライアント側に返す。
- 受け取った噂を表示する。
ユーザーの認証は求めません。
ユーザー認証有りにすればとれるつぶやきの数が増える等メリットはあるのですが、遊ぶ上でのハードルは下げたかったので。
「こんな怪しげなサイト、認証してまで遊ばない!」
と思う人、かなりいるでしょうし。
使用言語等
クライアント側の言語はHTML5、CSS、JavaScript(というか
jQuery)です。
あとCSS Frameworkとして
Bootstrapを使っています(デザイン能力が乏しい開発者の強い味方!)。
サーバ側はPHPとMySQLです。
OAuthやキャッシュの絡みでいくつかライブラリ使いました。
Yahoo Developerが提供するAPIは種類が多い上にアクセス制限ゆるめなのでかなりお薦めです。
公開前
企画〜開発の段階で考えたことや取り組んだことは以下の通りです。
楽しめるコンテンツであること
使った人が楽しめるようにしたいと強く思いながら作りました。
これまで作った診断系は分析してそれをそのまま表示するだけで、楽しいという要素が薄かったので、私の中での新境地開拓的な気持ちで。
噂の内容の詳しい説明は遊ぶとき興醒めでしょうからやめておきます。
TwitterやYahoo!のAPI制限エラー対策
開発者の方々の多くはご存知でしょうが、TwitterにもYahooにもAPIの使用回数制限があります。
つぶやきの取得、TwitterアイコンURLの取得、つぶやきからのキーフレーズの取得それぞれ回数の上限があります。
ちなみに現在、Twitterのsearch APIは180回/15分、Yahooのキーフレーズ抽出APIは50000回/1日。
毎回毎回生成の度にAPIにアクセスしていたら、Yahooの方はともかく、Twitterの方はあっという間にこの回数制限に引っかかってしまいます。
ですので、一回噂生成のために必要なデータを取得したら、それは一定期間DBに保存するようにしました。
ユーザー名を入れる
↓
そのユーザー名で過去の一定期間内に利用がなければAPI通信、利用があれば取得済みのデータを使う
という流れです(本当はもうちょっとだけやっていることありますが、ざっと説明すると)。
先頭に@が入っていても結果を出す
Twitterユーザの性質なのでしょうが、アカウント名の入力で頭に@を入れる人がけっこう多い(これまでの診断系コンテンツの運営で気づいたこと)。
ですので、@が先頭に入っていてもそれを無視するようにしました。
他にもRTのつぶやきは生成からはずすとか、細かい処理は色々と挟んでいます。
適切な表示情報量
最初は一回の生成で一個の噂を表示するように作っていました。
ただ、意味が通る噂と意味が通らない噂が混在しているので、一個ずつだとコンテンツの意図が伝わりづらいというか「なにこれ意味不明」と思われて終わる可能性が高いような……。
ということで、一度に三個ずつ表示するようにしました。
試してみると一個だと少ない、五個だと多いと感じたので。
公開初日(2013.4.10 水曜)
公開したのはこの日の午後8時30分頃でした。
さあ、ついに公開!
ちょっとは使ってもらえると嬉しいな〜と思いながらGoogleのリアルタイム検索を見ていると、ぷよぷよの連鎖を思わせるつぶやきの連鎖で訪問者数がぐんぐんと上昇上昇急上昇。
ファイヤー!
アイスストーム!!
ダイアキュート!!!
Twitterすごい!
Twitter恐い!
リアルタイム検索って3桁になることあるんですね!
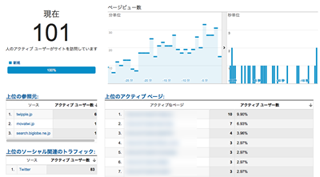
前に
この英語学習記事ではてなブックマークのホットエントリーに載って1000ブクマしていただいたときと同じぐらい、あるいはそれ以上?の勢いに到達。
他コンテンツでのcronの呼び出し回数調整
これらはcron(設定しておくと定期的に自動でプログラムを動かしてくれるやつ)を使ってTwitterからつぶやきの取得を行うことで結果を表示しています。
そこそこ頻繁にcronでの取得を行っていたんですが、その取得間隔見直しを行いました。
なにか問題があったわけではないのですが、通信処理は早いうちに減らしておきたかったので。
公開2日目(2013.4.11 木曜)
Twitterで盛り上がるのなんてせいぜい1日だろうと考えていたのですが、2日目以降もアクセス数は減らず。
というか、どんどん増えました。
噂のパターン追加
嬉しいことに十個も二十個も噂をつぶやいてくださる人が多数いました。
これだけたくさん遊んでいただくと、噂のパターンがあっという間に枯渇してしまう!
ということで噂の文章の追加を開始しました(以降ほぼ毎日追加中)。
HTML/JavaScriptのバグ修正
コードのケアレスミスがいくつかあったので修正。
指摘してくださった方々本当にありがとうございます。
IEこそ念入りにチェックしなければいけないとわかっていながらもなかなか……。
公開3日目(2013.4.12 金曜)
#あなたの噂、がついているつぶやきを対象から削除
噂を生成する際、あなたの噂のハッシュタグがついたつぶやきをはずすようにしました。
そうしないと、延々と同じワードばかりが抽出されてしまうので(抽出されたワードが本コンテンツ経由でつぶやかれることでさらに抽出されやすくなってしまうということ)。
データ保存絡みのミスを修正
データを保存する際、最初の一回だけ保存しておけばいいものを二回目以降も保存しているケースがあったのでそれを修正。
保存されていることの確認はしていても、上書きされていないことの確認は怠っていたんです。
公開4日目(2013.4.13 土曜)
エラー発生時にページのリロードを求めない
噂生成プログラムの呼び出し失敗、DBへの保存失敗、TwitterAPIとの接続エラー、YahooAPIとの接続エラー等、想定されるエラーは多数あります。
それらが発生した際、ページをリロードしなくとも生成するのボタンを押すだけで済むように改善しました。
ユーザのストレスを軽減させられるかなと。
Yahoo APIへの送信エラー修正
Yahoo APIへのデータの送信でエラーを発見してそれを修正しました。
送信するデータがフォーマットに適さないことがあるという初歩的なものでした。
ページのデザイン変更
「公開して4日目でもうかよ!」
とつっこまれるの覚悟の上でページのデザインを修正しました。
デザイン面についてちゃんと考えていなかったのばればれですね。
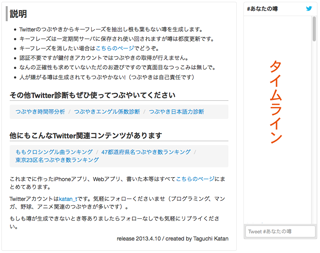
噂の生成部分はいじらず、その下にある説明部分の右カラムにTwitterのタイムラインを入れてみました。
あと、他のページに誘導できるようにリンクを増やしてもみました。
せっかく来てくれたのだから他のコンテンツも見てもらいたいし、せっかく来てくれたのだからまた来てほしいし。
「訪問者が一見さんで終わらないための方策なんて企画の段階で考えておくべきことだろう!」
と自らをつっこみながら対応しました。
「たくさん人が来てくれるにはどうしたらいいか」
は作るときにけっこう考えるんですけど……
「たくさん人が来てくれた後にどうするか」
はなかなか考えが及ばないものですよね(言い訳)。
保存データの自動削除
アイコンのURLとか、噂を生成するための元データとか、いろいろとサーバで保持しているのですが、訪問者の上昇に合わせてこれらのデータ件数ももちろん上昇!
こんな勢いで増えることは想定していなかった!!
そりゃあ、万単位のアカウントで遊んでいただいていればデータ数もそれ相応になりますよね。
一定期間を過ぎたデータは流用しない仕組みですが、流用しなくなった不要なデータの削除処理をまだ組み込んでいませんでした。
基本的にAPIで取って来られる機密性がないデータだけで、しかも期間過ぎたデータはアクセスもされないので、削除については後で考えればいいやと思っていたんです。
(鍵付きアカウントの人がこのアプリで遊ぶためだけ一時的に鍵をはずして再び鍵をかけた後に気にすることはあるでしょうが)
「早急に対応しないとまずい!」
というところまでは全然行っていなかったですが、忘れた頃にまずくなりそうなので自動削除に着手しました。
公開5日目(2013.4.14 日曜)
データベースアクセス順序の修正
これまでデータの取得と保存は以下の順序で行っていました。
- 該当アカウントのつぶやきデータの有無をデータベースに確認
- なければTwitterから取得して保存
- 噂用のキーフレーズ有無をデータベースに確認
- なければつぶやきデータをYahoo APIに送信して噂用のキーフレーズを取得して保存
けど、最終的な噂用のキーフレーズがすでにある状況では途中のつぶやきデータいらないんですよね。
データベースを見に行く必要すらない。
ですので、まずは噂用のキーフレーズの有無を最初に確認し、無いときだけつぶやきデータを取得しに行くように変えました。
データベースへのアクセス部分は翌日さらに手を加えています。
他の診断コンテンツからリンク
過去に作った他の診断コンテンツから噂生成へのリンクを貼りました。
噂生成から他の診断コンテンツに行ってくださる人が多くて、そういう人たちはまた噂生成に戻りたいケースもあるでしょうから。
本当はコンテンツが増えたら自動で関連ページも更新されるようにしなきゃですよね。
それぞれのコンテンツが構造上分断されている現状をしっかり直したい……。
公開6日目(2013.4.15 月曜)
生成時にサーバからまとめてデータを渡すように変更
生成ボタンを押してサーバから返ってくる噂は、もともと3つ(表示1回分)だけでした。
けれどこの日からまとめて返すようにしました(いくつ返すかはまだ調整中ですが、30回分程度)。
返ってきた噂を順番に表示し、すべて表示しきってストックが空になった段階で再度サーバとの通信を行います。
来訪者が生成を一度しか行わなければむしろ通信量増えて改悪なのですが、多くの方々は生成ボタンを何度も押してくれていそうなので。
この対応で何度も生成を行った際の通信回数を激減できるようになりました。
前から「いずれこうしたい」と思っていた仕様をやっと実装できた感じです。
生成ボタンを押す度に通信があると、連打した場合サーバにかなり負荷かかってしまうので。
リリース前に実装しておけよって話ですね。
データベースへの保存処理改善
前日の項に書きました通り、つぶやき取得時と噂用のキーフレーズ取得時の二回、データベースへの保存を行っていました。
これを噂用のキーフレーズのみの保存へと変えました。
最終的なキーフレーズさえあればつぶやきそのものは不要なので。
入力フォームの表示をJavaScriptファイルの読み込み完了まで待つ
サーバとの通信はJavaScriptで行っています。
JavaScriptのファイルがロード完了していない段階で生成するのボタンを押しても動作しません。
ですのでロードが完了するまでは入力フォームを表示しないようにしました。
ボタンだけ消しても良かったのですが、表示されるまでの秒数はかなり微々たるもの(おそらくだいたいの環境で1秒未満)ですし、フォームがまとめて出た方が出現に気づきそうなのでこうしました。
公開7日目(2013.4.16 火曜)
ブックマークのリンク先修正
本コンテンツはURLの後ろに?userid=というパラメータをつけることでそのユーザーの生成結果を表示することができます。
「この噂をつぶやく」のボタンを押すとこのユーザーID付きURLでTwitterにつぶやかれます。
本コンテンツの上部についているはてなブックマークやEvernoteへの登録ボタン(↓のスクリーンショット)は
AddThisというサービスを利用させてもらっています。

AddThisはURLを自動で設定してくれます。
そのため、Twitterのつぶやきからたどってたどり着いた場合、これらの登録がユーザーID付きURL(たとえばhttp://www.paper-glasses.com/twirumor/index?userid=katan_t)で行われていました。
「今後仕様変更してパラメータが変わることもあるかもしれない」
「ブックマークサービスでの登録数がURL毎に分散してほしくない」
といった理由があり、常にパラメータ無しのURL(http://www.paper-glasses.com/twirumor/)を返すように変更しました。
最後に
ということで公開前から公開1週間までの対応内容をざっとまとめてみました。
別に公開1週間で落ち着いたわけではなく、むしろこの頃よりもこの後にアクセスが急増してまた色々と対応したのですが、まあ書きすぎると取り留めがなくなってしまいますので。
(機会があれば別のタイミングで書くかも?)
今回のコンテンツリリースにおいて、なによりもTwitter上で数えきれないほど多くの方々が楽しんでいる様子を見ることができて嬉しかったです。
プログラミングをしてきてよかったと心底思うことができました。
心より感謝申し上げます。